
Musings on noun classification
Published:
Noun classification is a significant aspect of the grammar of Niger-Congo B languages.
For people who are interested in learning a language that belongs to the family, you need to understand that the phenomena is one of the most important things to master since it is crucial to ensure that words agree with each other, where appropriate, in the formation of sentences. For instance, the isiXhosa sentence “hlamba izitya ngoba zimdaka!” (Wash the dishes because they are dirty) is sensible while the sentence “hlamba izitya ngoba simdaka” (Wash the dishes because it is dirty) is not correct despite the minor difference in the isiXhosa source text. There are a variety of resources that one can find online to learn the notion of noun classes (e.g., https://quizlet.com/za/887926330/zulu-noun-classes-flash-cards/). To the best of my knowledge, these are manually created!
Existing work
Unfortunately, from a computing perspective, modelling noun classes has been largely neglected. The challenges associated with the task may not be clear, especially to people who work on high-resourced languages. In fact, if you fit that description, you may wonder why one cannot simply rely on a dictionary, or create resources in the same vein as Wordnet or Framenet that have noun class information. The short answer is that paper dictionaries for most languages are dated and creating lexical datasets is possible, to some extent, for only a handful of Niger-Congo B languages. For instance, the resources created by Eckart et al. 2019 are a good example since the model and associated dataset has noun class information. Unfortunately, if you want to tackle the problem for all, or most, NCB languages then you have to recognise that the assumption that there is guaranteed access to ‘open’ paper dictionaries that you can use to create resources that are findable, accessible, and reusable goes out of the window! At best, you may only be able to create large datasets using paper dictionaries published in the 1800s.
Despite the challenges that I have highlighted, I must mention that people have been working hard on different aspects related to noun classification. For instance, there are interesting efforts aimed at pinning down the semantics of noun classes and possibly creating an ontology (Keet, 2024). We have also created noun classifiers for isiZulu (Mahlaza et al., 2025; Sayed et al., 2025) and Sepedi (Alex and Jonathan’s work on Sepedi is not published) using a variety of different methods. A major challenge that we faced was the lack of dataset(s)!
Our efforts relied on relatively limited data, in terms of the languages supported, and we could not share the datasets since we had to manually extract them from recent paper dictionaries. The effort required to extract the data, while semi-automated, still required some effort to manually clean it. With that context, I’ve been curious about the extent to which one can rely on manually annotated and open datasets extracted from the Internet as a basis for building noun class identification models. Specifically, I’ve been wondering to what extent one can rely on the SADiLaR datasets (Gaustad, 2024), as an example, to build a multilingual model for predicting noun classes.
SADiLaR data
The first challenge with relying on the SADiLaR dataset(s) is that one needs to identify the nouns and their classes, since it includes a number of parts of speech. We iterated over all the words found in the datasets, extracted words that contain exactly three morphological tags and filtered out everything that does not include the following annotations: NprePre (i.e., the augment), Bpre (noun prefix), and NStem (noun stem). Our process produced the following data sizes:
| Train size | Valid size | Test size | |
|---|---|---|---|
| IsiZulu | 702 | 180 | 121 |
| IsiXhosa | 843 | 217 | 145 |
| IsiNdebele | 765 | 196 | 132 |
| siSwati | 323 | 83 | 56 |
Overall, the distribution of the nouns per class is given below:
| IsiNdebele | siSwati |
|---|---|
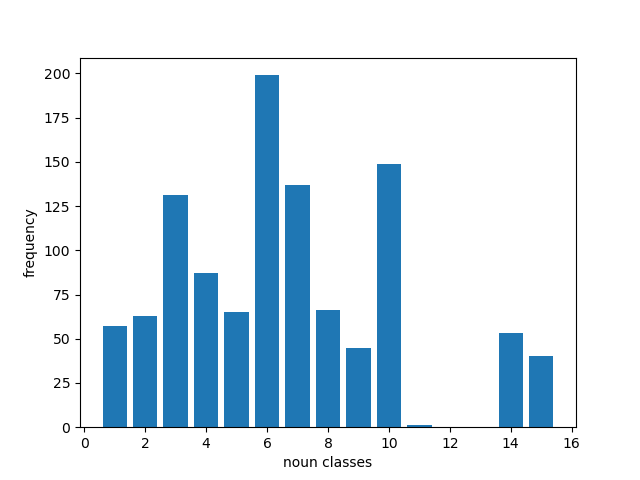 | 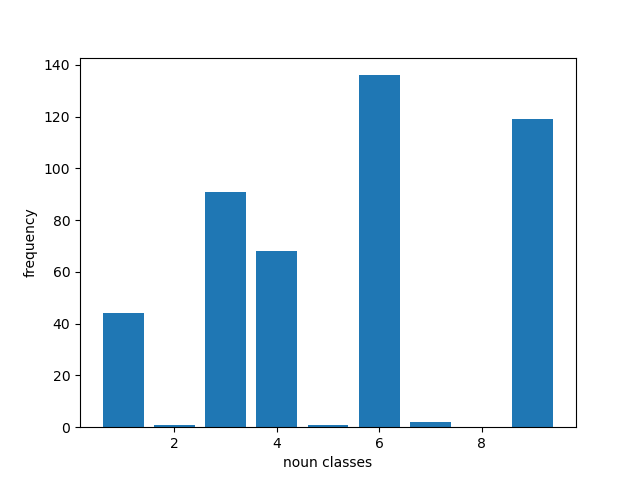 |
| IsiXhosa | IsiZulu |
|---|---|
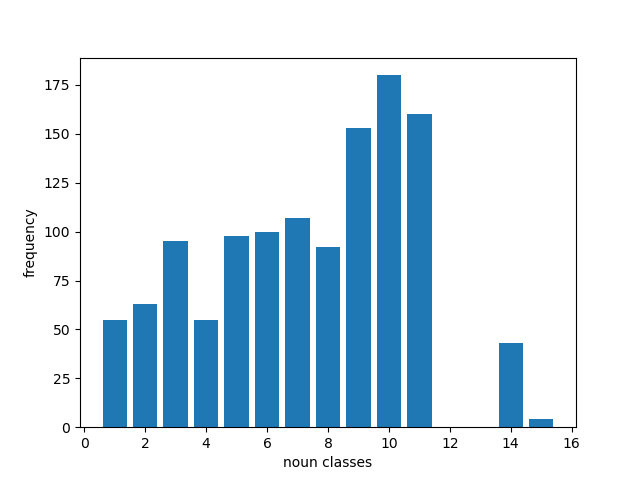 | 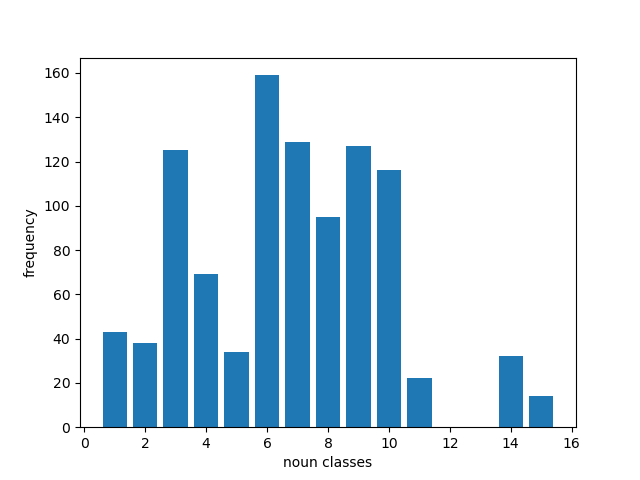 |
For basic testing, let each noun be represented by an input vector, obtained by tokenising the strings using Nguni-XLMR-large (Meyer, 2024). We trained a simple Multilayer Perceptron (MLP) using the dataset to obtain a multilingual model to cater for all four Nguni languages. The performance of the model is given in the table below:
| Prec | Rec | F1 | |
|---|---|---|---|
| Micro | 0.11 | 0.11 | 0.11 |
| Macro | 0.03 | 0.10 | 0.05 |
This performance is terrible! In fact, the issue is not that we are relying on a simple model because we’ve also tried relying on the Nguni-XLMR-Large model and the results are different but equally disappointing. The issue is the dataset!
It is too small, the distribution of the nouns across the different classes is terribly uneven, and I doubt a model built on such data might be useful outside government documents (even if the performance was great on this small dataset).
References
- Keet, 2024: https://www.utwente.nl/en/eemcs/fois2024/resources/papers/
- Mahlaza et al., 2025: https://aclanthology.org/2025.loreslm-1.35.pdf
- Sayed et al., 2025: https://aclanthology.org/2025.resourceful-1.23.pdf
- Meyer, 2024: https://huggingface.co/francois-meyer/nguni-xlmr-large
- Eckart, 2019: https://drops.dagstuhl.de/entities/document/10.4230/OASIcs.LDK.2019.17
- Gaustad, 2024: https://repo.sadilar.org/items/33a71474-0847-43d0-a125-b0a971b0bbba, https://repo.sadilar.org/items/aec37cd3-0e74-42ac-a578-4c71fafb3bfe, https://repo.sadilar.org/items/df53f13b-794b-441b-a02f-3fd673803932, https://repo.sadilar.org/items/4227c37a-f4b9-47dc-9b5e-e2e94218350b